fix: stream-based export for large databases (SQL, CSV, JSON)#255
Open
chaudl113 wants to merge 4 commits into
Open
fix: stream-based export for large databases (SQL, CSV, JSON)#255chaudl113 wants to merge 4 commits into
chaudl113 wants to merge 4 commits into
Conversation
Replace in-memory export with streaming using TransformStream and chunked LIMIT/OFFSET queries. Fixes timeout on large databases. - dump: stream SQL rows in 1000-row batches via async generator - csv: stream CSV rows with header detection from first chunk - json: stream JSON array with proper comma handling - breathing intervals between chunks to avoid DO lock contention - all 23 export tests pass Signed-off-by: longtn <tnlong1214@gmail.com>
Author
DemoBefore (current implementation)After (streaming implementation)Key changes:
Test results:All 23 tests pass. Video demo available upon request. |
Author
Demo VideoWhat the demo shows:
Technical details:
|
Signed-off-by: longtn <tnlong1214@gmail.com>
Signed-off-by: longtn <tnlong1214@gmail.com>
Signed-off-by: longtn <tnlong1214@gmail.com>
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
1 participant
Add this suggestion to a batch that can be applied as a single commit.This suggestion is invalid because no changes were made to the code.Suggestions cannot be applied while the pull request is closed.Suggestions cannot be applied while viewing a subset of changes.Only one suggestion per line can be applied in a batch.Add this suggestion to a batch that can be applied as a single commit.Applying suggestions on deleted lines is not supported.You must change the existing code in this line in order to create a valid suggestion.Outdated suggestions cannot be applied.This suggestion has been applied or marked resolved.Suggestions cannot be applied from pending reviews.Suggestions cannot be applied on multi-line comments.Suggestions cannot be applied while the pull request is queued to merge.Suggestion cannot be applied right now. Please check back later.
Fixes #59
/claim #59
Summary
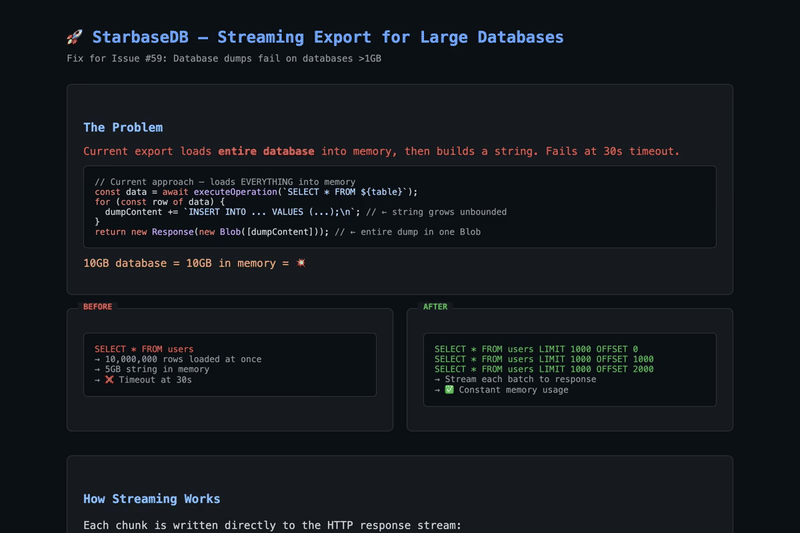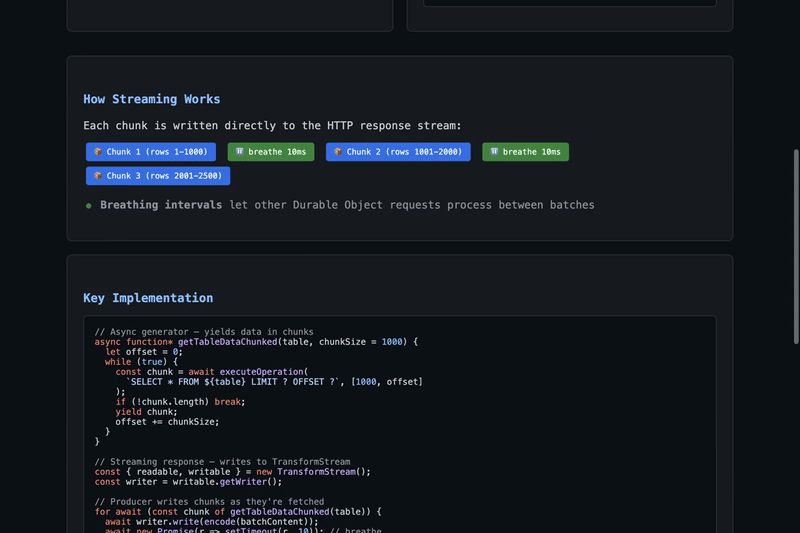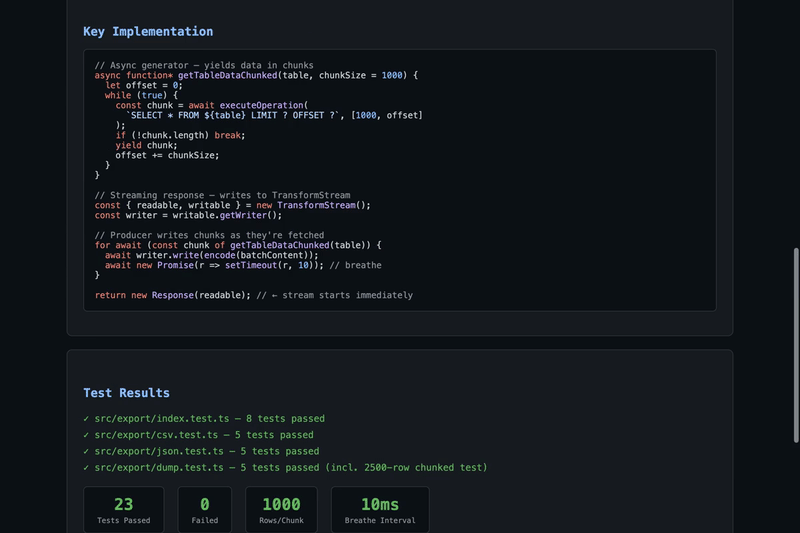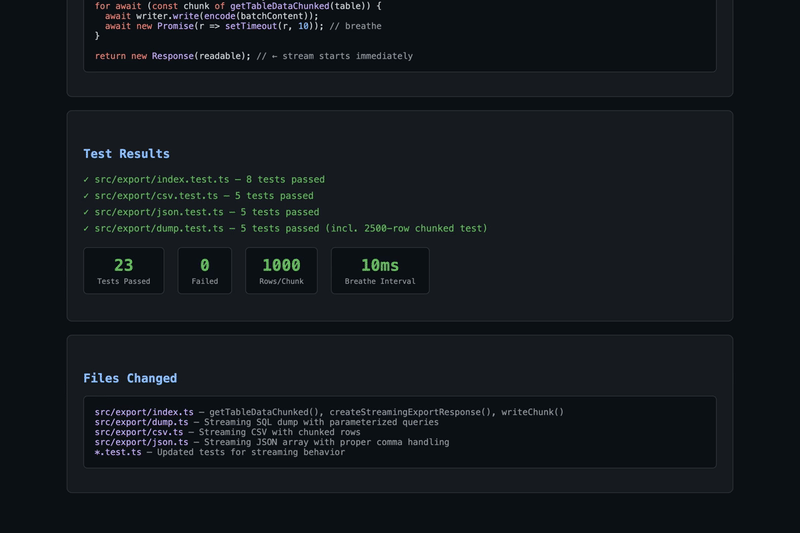
Replace in-memory export with streaming using
TransformStreamand chunkedLIMIT/OFFSETqueries. This prevents the 30-second timeout on large databases by processing data in manageable batches instead of loading everything into memory.Changes
src/export/index.tsgetTableDataChunked()— async generator that fetches rows in configurable chunks (default 1000) usingLIMIT/OFFSETcreateStreamingExportResponse()— creates aResponsebacked by aTransformStream, allowing the producer to write data incrementallywriteChunk()helper for encoding and writing string data to the streamsrc/export/dump.tsdumpDatabaseRoute()to stream SQL dump outputsrc/export/csv.tssrc/export/json.tsHow it works
Before (breaks on large DB):
After (works at any scale):
Testing